
In mid-2023, during the absolute peak of the generative AI hype cycle, there was a large, frantic gold rush for a suddenly lucrative new job title: The Prompt Engineer.
I embarrassingly admit that I bought into the panic. I paid $499 for an online course that promised to teach me the “secret” language of Large Language Models (LLMs). People were selling entire Notion templates claiming they had discovered the precise “magic words” to make ChatGPT perform well.
The strategy usually involved typing bizarre, incredibly baroque psychological instructions like: “Assume the persona of a Harvard Economics Professor with 30 years of deep academic experience. Think step-by-step. Take a deep breath. Start your answer with the word ‘Certainly’.”
Looking back, it felt incredibly silly. It felt like casting a mechanical spell. If you got the exact phrasing right, the machine worked. If you missed a single verb, the machine suddenly hallucinated wildly.
By 2026, that rigid, linguistic version of prompt engineering is completely dead.
Modern Large Language Models like OpenAI’s GPT-5, Google’s Gemini 3.1 Pro, and Anthropic’s Claude 3.5 Sonnet are simply too structurally sophisticated to need “magical” phrasing. They understand abstract intent well. The operational bottleneck in AI development is no longer how you phrase the question.
The bottleneck is entirely defined by what specific information surrounds the question.
Welcome to the technical era of Context Design (frequently referred to in enterprise tech as Context Engineering). If you genuinely want to build autonomous tools, manage agents, or design workflows that actually generate reliable revenue in 2026, this is the large paradigm shift you urgently need to master.
Why Traditional Prompt Engineering Died
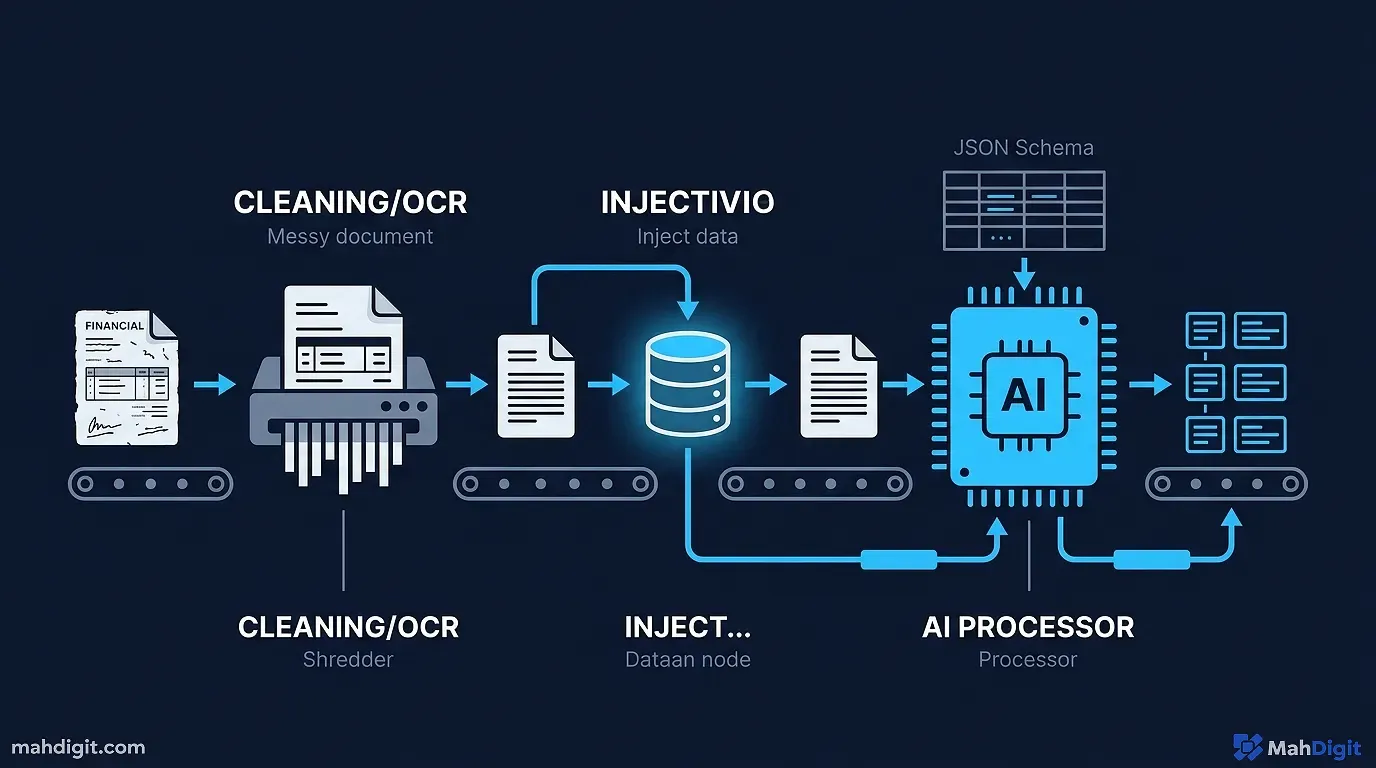
The swift death of traditional “magic word” prompt engineering was mechanically inevitable. It was driven by two large architectural advancements at the foundational labs:
- large Instruction Tuning: AI labs tuned their base models using techniques like RLHF (Reinforcement Learning from Human Feedback) to stubbornly follow implicit instructions intuitively. You no longer need to explicitly tell a model to “think step-by-step” before answering because iterative, chained reasoning is now built natively into its base architecture. The model does it automatically in a hidden background process before rendering the final text.
- Autonomous Prompt Optimization: When you type a simple prompt into an advanced Agentic interface (like the Cursor IDE or Google Antigravity), the underlying system actually securely intercepts your messy prompt. It rewrites it internally to structurally optimize it for the specific LLM being used, and then sends the heavily optimized API request. The AI software is mechanically better at prompting the core AI model than you will ever be.
As I outlined extensively in my practical guide on no-code AI automation, we have moved past Chat interfaces and directly into Agentic workflows. Intelligent agents do not care about your elegant, witty phrasing; they care exclusively about rigid data constraints.
What Is Context Design and Why It Replaces Prompting

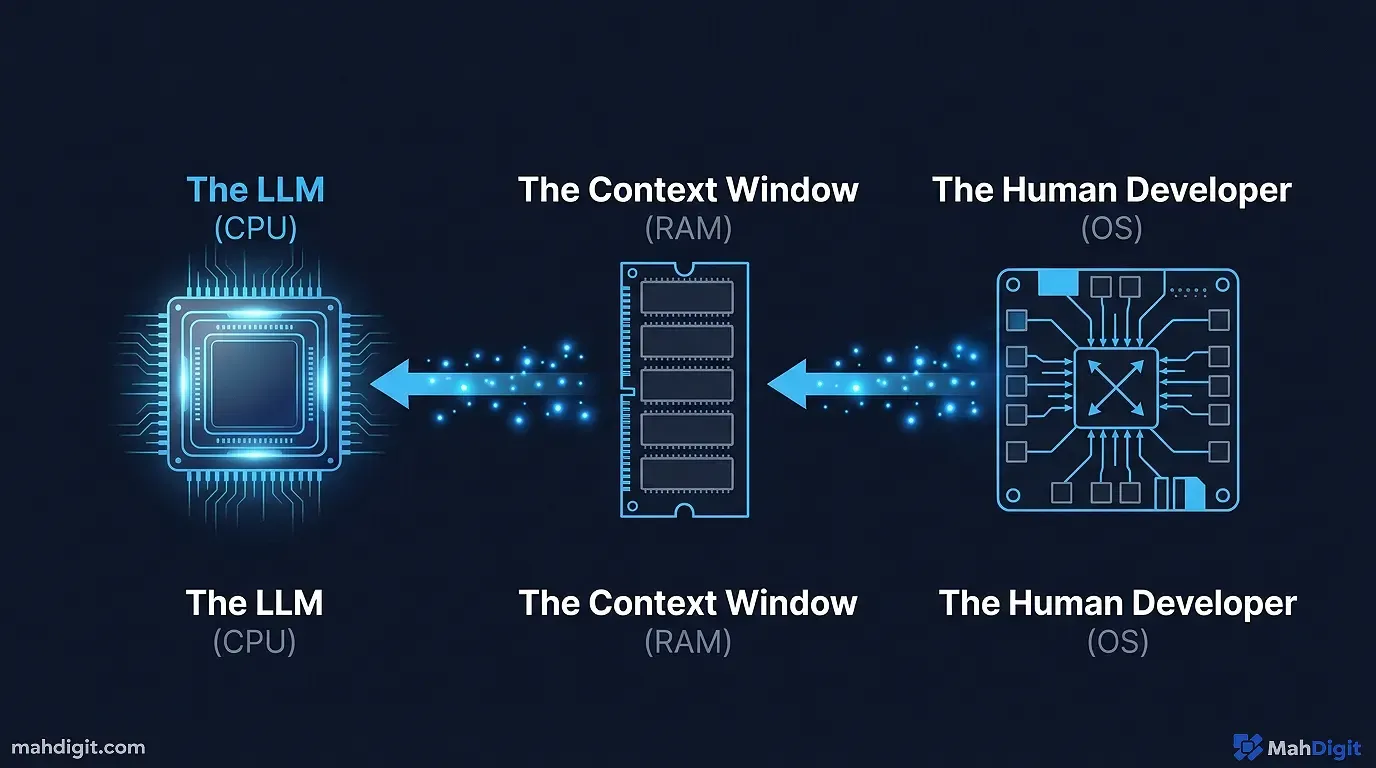
Andrej Karpathy (former Director of AI at Tesla and influential OpenAI researcher) popularized the perfect technical analogy for this specific shift in human-computer interaction.
Think of the underlying Large Language Model as the CPU of a computer. It provides raw, mathematical processing power. The Context Window (the literal amount of raw text or tokens the AI can process and “remember” at any one precise moment) is the computer’s RAM.
You, the human developer, are the Operating System.
Your job is no longer to be a slick “prompt whisperer.” Your job is to act as the gatekeeper deciding ** what files, proprietary documents, and structural instructions need to be efficiently loaded into the limited RAM before the CPU is allowed to execute the task.
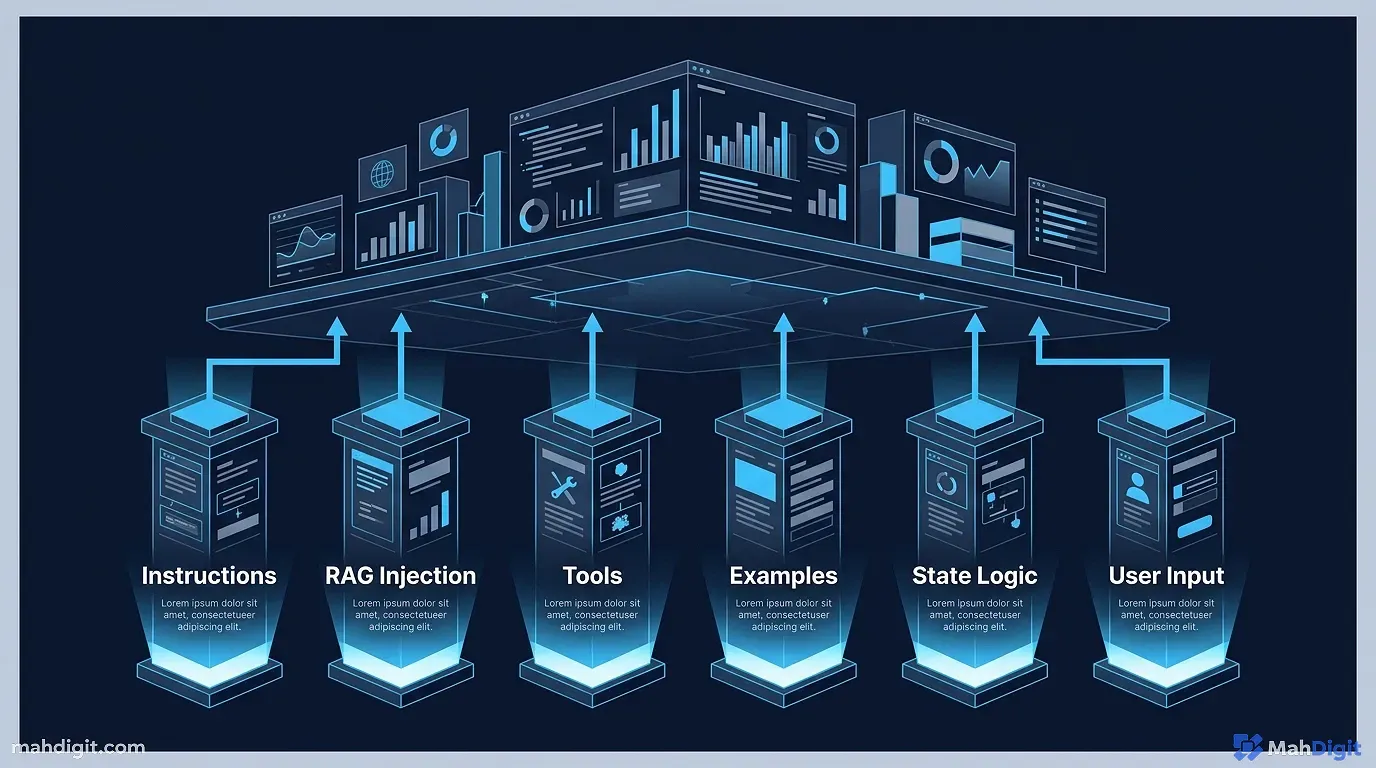
Context Design is the systematic architecture of information. It involves meticulously shaping six specific structural elements programmatically before the end-user ever types a single word into the chat box.
The 6 Pillars of Context Design
If you are currently building a commercial AI tool, a Slack automation, or a Micro-SaaS platform (which I teach you how to do over a weekend in AI tools for developers), your hidden backend “prompt” is rarely just a text string.
It is actually a modular, rigidly defined software architecture built squarely upon these six distinct operational pillars:
1. The System Instructions (The Laws of Physics)
These are your unbreakable, fundamental rules that govern the AI’s entire existence. You inject these into the system role of the API call.
Example: “You are a customer support agent for Acme Corp. You may ONLY answer questions using the exact knowledge base text provided below. If the answer to the user’s query is not explicitly found in the appended knowledge base, you must output ‘I cannot assist with that.’ You must never guess, assume, or retrieve external information.”
2. Retrieval-Augmented Generation (RAG)
This is the dynamic memory injection. You purposefully design the backend system to rapidly fetch the specific user’s past purchase history from a PostgreSQL database, or scrape the company’s internal Confluence wiki. You programmatically inject that raw text directly into the context window right before the AI reads the user’s question and generates a reply.
3. Tool Definitions (The Mechanical Hands)
You cannot just tell an AI to “Search the web.” You must mechanically teach the AI what specific APIs it is legally allowed to use. This requires writing strict JSON Schemas defining the tools. You must define precisely what parameters the ‘Google Calendar API’ requires (e.g., a properly formatted datetime string) and structurally explain what error codes the API might stubbornly return.
4. Few-Shot Examples (The Strict Formatting Guide)
LLMs are notoriously erratic at formatting. The golden rule of Context Design is providing 3 to 5 perfect, flawless examples of the desired user input and the exact desired machine output within the system prompt. This implicitly forces the AI to mirror the structural formatting how your downstream database requires it.
5. Abstract State Management (The Short-Term Memory)
Designing how the long conversation history is handled. Simply appending every single message to the API call will quickly overflow the context window and trigger a large API failure. Context designers build specific truncation logic. They force a cheaper, faster LLM to continuously summarize the conversation every ten messages to ensure the primary AI remembers what was said twenty minutes ago without blowing the API budget.
6. The User Input (The Final Trigger)
This is the actual, messy question the frustrated user typed into the text box. In 2026, this is ironically the absolute least important part of the entire AI software stack. Your robust context design should handle 95% of the logic before this text string is ever evaluated.
Feature Comparison: The 2023 Meta vs. The 2026 Meta
To make the stark contrast clear, here is how the industry shifted from linguistic tricks to structural data engineering.
| Concept Focus | 2023 Prompt Engineering | 2026 Context Design |
|---|---|---|
| Core Objective | Coaxing the AI to answer correctly | Restricting the AI’s data perimeter |
| Primary Skill Required | Linguistic cleverness / NLP Hacks | Systems architecture / Data structuring |
| Output Formatting | Begging (“Please use JSON format”) | Strict JSON Schema enforcement in API |
| Handling Hallucinations | Telling it to “Think step-by-step” | Grounding via deep RAG injection |
| Job Role Equivalent | Copywriter / Translator | Software Systems Architect |
If your entire AI strategy relies heavily on telling the LLM to “act like an expert,” you are operating functionally three years in the past.
Context Design in Practice: A Real-World Example
Here is a , real-world practical example. You want an AI to summarize a messy, incredibly dense 50-page Q3 earnings call transcript for Nvidia.
The Obsolete 2024 Prompt Engineering Approach: You lazily paste 50 pages of raw text into ChatGPT and type: “You are an expert Wall Street financial analyst with twenty years of hedge fund experience. Read this attached transcript thoroughly. Think carefully. Extract the top three financial risks facing the company and definitively format them as bullet points. Do not hallucinate.”
The Result: A generic, incredibly shallow summary. It probably misses the nuanced supply chain risks secretly buried by the CEO during the Q&A section, simply because the AI lacked a structural analytical framework to evaluate the raw data against. It just regurgitated the loudest keywords.
The Modern 2026 Context Design Approach: You do not type a manual prompt. You build an automated workflow architecture pipeline (perhaps using the exact autonomous orchestration tools mentioned in best free AI tools):
- The Tool Layer: You programmatically pipe the raw transcript through a dedicated OCR and text-cleaning API script. You ensure the AI is not needlessly struggling to process weird PDF line breaks, header artifacts, or bizarre character encodings.
- The RAG Injection Layer: You programmatically inject a dense JSON file containing the company’s previously stated Q2 risks and Q1 supply chain bottlenecks. Why? So the AI has a rigid, historical baseline to compare the new Q3 statements against to spot major discrepancies.
- The Schema Enforcement Layer: You do not ask for “bullet points.” You pass a rigid, nested JSON Schema structure to the OpenAI API explicitly requiring a specific
Risk_Title, a numericalSeverity_Score (1-10), and a mandatoryDirect_Quote_Citationthat must match the transcript . - The Final Execution: You mechanically pass the clean text, the historical baseline data, and the strict structural schema to the heavy model (like Claude 3.5 Sonnet) operating at temperature 0.0 (maximum determinism).
The Result: A perfect, completely verifiable, structured, machine-readable data extraction ready to be instantly dropped into a relational database or a live financial dashboard without human editing.
The Evolution of the Developer
If you find yourself constantly frustrated because the AI outputs terrible, generic, or wildly hallucinated code, your prompt phrasing is almost certainly not the primary issue.
You are failing to provide the AI with the necessary background data (the context) to actually solve the problem. You are asking a brilliant but completely blind architect to build a skyscraper without giving them the soil reports, the municipal zoning laws, or the steel load calculations.
This specific operational failure is why I harp so on writing detailed “Architecture Prompts” before writing a single line of code in modern IDEs like Google Antigravity. (If you missed that workflow, you urgently need to review my breakdown of AI tools for developers).
You must define the constraints, supply the necessary environmental data, and then lock the doors so the AI cannot wander off into the weeds.
The Hidden Mechanics: API Configuration Tuning
Beyond just structuring the text documents and defining the tool schemas, a true Context Designer understands the underlying mechanical API parameters that dictate how the CPU (the LLM) processes the loaded RAM (the context window). You are not just tossing text at a black box; you are actively turning physical dials.
Too many “prompt engineers” complain that an AI’s output is wildly hallucinated or overly rigid, without ever realizing they have fundamental API settings misconfigured in their backend environments.
1. The Temperature Dial (Controlling Chaos)
The absolute most critical dial in your Context Design arsenal is the temperature parameter. This setting directly controls the mathematical randomness of the neural network’s token prediction engine. It operates on a standard scale from 0.0 (absolute robotic determinism) to 2.0 (maximum chaotic creativity).
If you are a Context Designer building an automated legal contract extraction tool that reads PDFs and outputs precise liability clauses into a database, you must set the temperature to 0.0. You do not want the AI to “get creative” with a legal clause. You want it to extract what is on the page, word-for-word.
Conversely, if you are designing a creative brainstorming tool meant to generate bizarre, left-field marketing campaign ideas for a new energy drink, an low temperature will result in painfully boring, generic outputs. You must turn the dial up to 0.8 or 1.2 to actively force the model to take statistical leaps of logic and combine unusual concepts.
The linguistic phrasing of your prompt matters exponentially less than the physical configuration of the temperature dial when determining the consistency of your final output.
2. Top-P (Nucleus Sampling)
While Temperature controls the raw mathematical randomness, the top_p parameter (often called Nucleus Sampling) operates as an aggressive structural filter on the AI’s vocabulary. It limits the pool of potential next words the model is even legally allowed to consider before it applies the temperature randomness.
If you set the top_p to 0.1, the model is rigidly forced to only choose from words that comprise the most likely 10% of potential outcomes. It effectively creates a focused, specialized vocabulary.
A master Context Designer specifically uses top_p when forcing an AI to write dense technical software documentation or complex medical triage summaries. By heavily restricting the vocabulary pool, the AI is mechanically prevented from using vague, poetic adjectives or wandering off-topic into weird conversational tangents, regardless of what the user accidentally typed into the prompt box.
3. Strict JSON Schema Enforcement (“Structured Outputs”)
In late 2024, OpenAI formally introduced an API feature called “Structured Outputs,” which completely revolutionized backend Context Design and permanently killed the need to verbally beg the AI to “please format the final answer as a JSON string.”
Before Structured Outputs, developers had to waste valuable context window space typing out large, paranoid paragraphs threatening the AI: “Do not output any markdown formatting. Do not output conversational filler like ‘Here is your data’. Output ONLY a strict JSON object with the keys ‘name’ and ‘age’. If you fail to do this, the system will crash.” Half the time, the AI would still inexplicably append a polite “Sure thing! Here you go:” to the start of the string, crashing the downstream database instantly.
Today, advanced Context Designers simply pass a rigid, defined JSON Schema object securely within the API headers. The API provider (OpenAI, Google) guarantees at the systemic infrastructure level that the resulting output will 100% well match your provided schema, stripping away all conversational filler automatically.
You no longer explicitly prompt for structure; you rigidly engineer the data pathway to reject any unstructured thought.
The Future of Quality Assurance (Human-in-the-Loop)
As we rapidly pivot from manual prompt writing to automated context architecture, the actual daily job function of a human operator is shifting dramatically toward Quality Assurance (QA).
When you build a automated RAG pipeline that reads a 500-page medical textbook, chunks the text, stores it in a vector database, and uses it to answer complex diagnostic queries, you can no longer visibly “see” the prompt being executed. The system is entirely a mechanical black box running in the background.
Your job is no longer to tweak the exact adverb used in the system instruction. Your job is to rigorously build automated evaluation frameworks. You must write scripts that inject one thousand distinct, difficult test questions into the data pipeline every single night, evaluate how often the RAG system retrieves the wrong textbook paragraph, and log the failure rate.
If the system fails, you do not rewrite a prompt. You physically reconfigure the Python code that splits the textbook pages into smaller vector chunks, creating a cleaner context environment for the LLM to read the next day. This is the difference between a writer and an engineer.
Key Takeaways
We have permanently moved from a brief, silly era of linguistic manipulation to a permanent, technical era of rigid data architecture.
- Stop Buying Prompt Packs immediately. There are no secret, magical words that will magically make an LLM significantly smarter. Focus intensely on clear, direct, structural language and data formatting.
- The LLM is just a raw CPU. Your primary professional role is acting as the powerful Operating System, managing what data gets loaded into the AI’s limited context window (RAM).
- Context Design is modular. A robust, production-ready AI interaction requires strict System Instructions, dynamic RAG (data injection), explicit Tool Definitions, and Strict Output Formatting schemas well aligned together.
- Constraints create operational quality. The best Context Designers do not give the AI creative freedom; they intentionally build rigid cages of data and rules, forcing the AI to process only what is relevant to the immediate task.
- Engineering > Linguistic Flair: If your AI output is bad, do not rewrite your sentence. Fix your data pipeline. Look at what information the AI is blatantly missing to make the correct conclusion.
Prompt engineering was a temporary, brittle bridge crossing the gap between early chat models and true agentic workflows. Context Design represents the actual, sustainable, technical future of securely working with enterprise AI.
Build the structural environment well, and the AI will inevitably answer the question correctly. For more on how this applies to real tools, explore building an AI workflow and the deep dive into automating social media with AI.
